NVIDIA DGX H100은 고성능 AI 컴퓨팅을 위한 최첨단 시스템입니다. 이전 세대 대비 크게 향상된 성능과 효율성으로, 복잡한 AI 워크로드를 더욱 효과적으로 처리하는 데에 탁월합니다.
특히 강력한 하드웨어 구성과 고성능 네트워킹 능력을 가지고 있어, 대규모 언어 모델(LLM)이나 추천 시스템, 생성형 AI 트레이닝 및 추론 등의 다양한 영역에 사용되고 있는데요.
이 글에서는 NVIDIA DGX H100에 대한 상세한 제품 설명과 더불어, 도입을 문의하시는 고객님들께서 자주 질문하시는 17가지 정보에 대해 준비했습니다.
NVIDIA DGX H100 주요 특징과 기능
하드웨어 구성

NVIDIA DGX H100의 핵심 시스템은 8개의 NVIDIA H100 Tensor Core GPU에 있습니다. 각각 6,400억 개의 트랜지스터로 구성되어, 총 640GB의 GPU 메모리를 제공하고 있죠.
또한 시스템의 성능을 더욱 강화하기 위해, 듀얼 Intel Sapphire Rapids Xeon CPU와 2TB의 시스템 메모리를 탑재하고 있습니다. 기존 시스템이 가지고 있었던, GPU와 CPU의 균형 문제를 해결한 모델이라고 볼 수 있죠.
이외에도 30TB NVme SSD 스토리지를 포함하고 있어, 대용량 데이터에 대한 고속 접근도 용이합니다. 실제로 빅데이터 분석이나 AI 모델 훈련 과정에서 발생하는 데이터 병목 현상을 크게 줄어든 것을 확인할 수 있었습니다.
성능과 연결성
NVIDIA DGX H100에서 가장 주목할 만한 성능 지표는 FP8 정밀도에서 32 petaFLOPS의 컴퓨팅 성능을 제공한다는 점인데요. 이를 통해 복잡한 AI 작업을 훨씬 빠르고 효율적으로 수행할 수 있게 되었죠.
이렇게 높은 성능을 유지할 수 있는 이유는, GPU 간 연결에 사용하는 4개의 NVIDIA NVSwitch에 있습니다. 이 NVSwitch는 초당 7.2TB로 양방향 GPU 간 대역폭을 가지고 있어, 데이터 전송의 효율을 극대화한다는 장점이 있습니다.
소프트웨어와 활용
DGX H100 시스템은 DGX OS를 기본값으로 합니다. 이 설정은 Ubuntu Linux를 기반으로 최적화된 DGX 소프트웨어 스택이 특징인데요. 자연어 처리나 추천 시스템, 데이터 분석 등 다양한 AI 작업에 최적화되어 있어, 복잡한 AI 개발 프로젝트를 더욱 효율적으로 수행할 수 있죠.
확장성
NVIDIA DGX H100의 확장성 역시 주목할 만한 특징 중 하나인데요. 이 시스템은 NVIDIA DGX SuperPOD 시스템의 핵심 구성 요소로 활용할 수 있기 때문에, 대규모 AI 인프라 구축에 가장 이상적인 스펙을 가지고 있습니다.
특히 엔터프라이즈급 AI가 필요한 기업이나 연구 기관이 필요에 따라 컴퓨팅 능력을 탄력적으로 확장할 수 있죠. 앞으로 더욱 고도화될 AI의 요구 사양에 충분히 대응할 수 있을 정도로 유연한 확장성을 가지고 있습니다.
NVIDIA DGX H100 자주 묻는 질문 (Q&A)
한 SU(Scalable unit)의 권장 작업 시간은 어떻게 되나요?
데이터 센터가 이미 DGX SuperPOD에 적합하다고 가정할 경우 (즉, 추가 전력이나 냉각을 추가할 필요가 없을 때) 일반적으로 배치 전 작업 (현장조사, 장비조달 등)에 소요되는 기간은 ~12주입니다. 이후 배치부터 실제 작업 소요 시간은 일반적으로 4-6주가 추가 소요됩니다.
Rack에 있는 스토리지나 기타 장치를 위해 추가 전력이 필요한가요?
스토리지 및 기타 인프라 항목은 DGX SuperPOD의 개별 Rack에 있습니다. DGX H100 Rack과는 다른 전력 요구사항을 가지고 있습니다.
DGX를 설치하려면 hot zone(핫존)에는 어느 정도의 공간이 필요한가요?
필요한 최소 공간에 대한 정보는 도표를 확인해주시기 바랍니다.
자세한 정보는 NVIDIA DGX H100 and DGX H200 Pre-delivery Site Survey 에서 확인하실 수 있습니다.
또한, 서버 리프트를 작동시키기 위해서는 충분한 공간이 필요합니다. 단, 서버 리프트는 핫 존이 (hot zone) 아닌 콜드 존(cold zone)에서만 작동합니다.
상면 상온 온도 24C 인 40kW Rack 에 표시되는 풍량(CFM)의 양은 얼마인가요?
해당 정보는 DGX H100 웹사이트의 조사결과( NVIDIA DGX H100 and DGX H200 Pre-delivery Site Survey)를 통해 확인하실 수 있습니다.
Rack에서 하단 2대의 DGX H100 시스템과 상단 2대 사이에 간격이 있는 이유가 있나요?
필요 시 수평 Rack PDU 추가를 위한 것입니다. 또한 Rack 내부 공기 흐름을 원활하게 하기 위한 용도이기도 합니다.
DGX H100에서 인접한 공간으로 전달되는 소음과 진동을 줄이려면 어떻게 해야 하나요??
시스템에서 발생하는 소음의 양은 팬이 얼마나 세게 작동해야 하는 지에 따라 결정됩니다. 공급 공기가 차가울수록 팬이 덜 작동하고 시스템이 더 조용해집니다.
사양에 명시된 101데시벨은 30℃의 공급 공기에 대한 것으로, 이 수준에서는 팬이 80%로 작동하며 상당히 높은 수준입니다. 따라서 작업자는 서버 주변에서 작업할 때 귀마개 등 적절한 개인 보호 장비를 착용해야 합니다.
데이터 센터 룸 외부의 소음을 제한하는 소음 저감 전략을 수행하려는 경우, 건물 구조에 따라 다를 수 있으므로 전문가와의 사전 커뮤니케이션이 필요합니다.
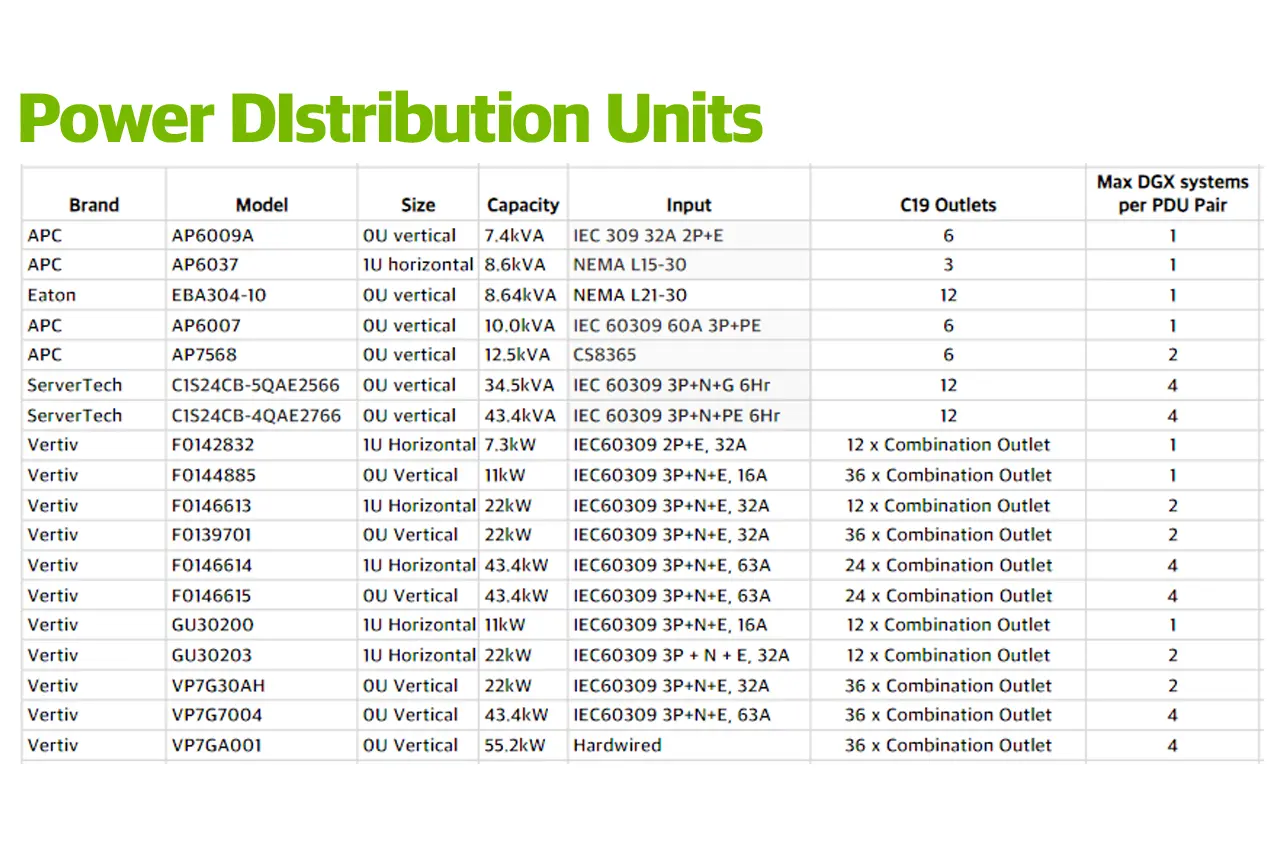
Rack 에 있는 4개의 시스템을 지원하려면 3개의 PDU로 전원 연결이 가능합니까?
Rack PDU가 적절한 수의 출력을 가진 유형이라면 3개의 PDU로 충분합니다.
Rack 당 평균 및 피크 전력 소비량은 얼마인가요?
전체 4 서버 Rack 프로파일의 경우 40.8kW, 2 서버 Rack 프로파일의 경우 20.4kW, 단일 서버 Rack 프로파일의 경우 10.2kW입니다.
0.4kW 에서 2 DGX H100 을 냉각하기 위해 적절한 방법은 뭘까요?
몇 가지 일반적인 냉각 최적화 기법에는 적절한 공기 차단 및 격리 Rack 사이에 공간을 배치하여 냉각 집중하는 등의 방법이 있습니다. 냉각 설계는 데이터센터 디자인에 따라 달라질 수 있습니다.
H100과 H100 NVL의 전력에 차이가 있나요?
DGX SuperPOD는 H100 SXM 폼 팩터 GPU가 포함된 DGX H100 서버를 사용합니다.
또한 PCIe 폼 팩터인 H100 및 H100 NVL GPU도 있습니다. SXM 버전은 GPU 간의 통신에 최적화 되어있으며, 다른 버전들보다 더 높은 전력/clock 으로 실행됩니다. 차이점은 H100 Tensor Core GPU | NVIDIA에서 확인 할 수 있습니다.
DGX H100 사이트의 전력 및 냉각에 대한 표준 가이드가 필요합니다.
NVIDIA DGX SuperPOD Data Center Design에 표시된 “데이터센터 설계 가이드”에서 실제 사례를 확인하실 수 있습니다.
NVIDIA는 Rack의 특정 규격이 지정되어 있나요?
예. NVIDIA는 사용할 Rack의 특정 브랜드나 모델을 지정하지는 않지만, Rack의 규격을 지정하고 있습니다.
Rack은 19인치 EIA 마운팅 이 있는 밀폐형 Rack의 경우 EIA-310 표준을 준수해야 합니다. Rack의 규격은 최소 24″ x 44″(600mm × 1100mm) 크기, 최소 48U 높이여야 합니다. NVIDIA는 30″ x 48″ x 52U (700mm × 1200mm) Rack을 권장합니다.
패치 패널 또는 Rack 스위치 상단을 사용하여 InfiniBand 케이블 길이 제한을 연장할 수 있습니까?
아닙니다. InfiniBand는 매우 고성능 아키텍처이며, 케이블 길이의 제한은 케이블의 일부 구간이 아닌 전체 신호 경로의 신호 감쇠 및 지연 시간을 기준으로 합니다. 패치패널 은 신호 감쇠를 악화시키고 Rack 스위치의 중간 상단에 있는 스위치는 Latency 를 증가시킵니다.
NVIDIA는 특정 Rack PDU 유형을 지정하나요?
그렇습니다. Rack PDU는 각 데이터센터에서 사용할 수 있는 전원 프로비저닝 을 준수해야 하며, 각 시장 지역에서 사용 가능한 브랜드를 따라야 하므로 NVIDIA는 특정 브랜드나 모델을 지정하지 않습니다.
하지만, NVIDIA SuperPOD 설계가 통합된 스마트 모듈, 네트워크 인터페이스, RestAPI 인터페이스, 온도 및 센서 프로브용 포트, 잠금 리셉터클, PDU 레벨 측정, 리셉터클별 원격 콘센트 스위칭, 시각적 회로 구분을 위한 빨간색, 파란색, 회색 외관 (옵션) 을 포함하는 rPDU를 포함 할 것을 권장합니다.
확장형 유닛을 몇 개까지 배포할 수 있나요?
일반적인 SuperPOD에는 최대 4개의 확장형 장치가 포함될 수 있지만, 추가적인 장치를 배치할 수도 있습니다.
DGX Rack의 빈 공간을 다른 IT 장비에 활용할 수 있나요?
DGX 스케일러블 유닛 (Scalable Unit) 은 설계된 솔루션이므로 공유 Rack에서 관련 없는 장비와 함께 사용해서는 안 됩니다. 또한 냉각 용량을 통합하기 위해 Rack의 간격을 띄워 배치한 경우에도 DGX H100 Rack 사이의 공간에 관련 없는 장비를 배치를 지양합니다.
DGX H100 시스템 아키텍처가 포함된 DGX SuperPOD에 대한 추가 정보는 어디에서 찾을 수 있나요?
- NVIDIA Docs 웹사이트에서 DGX SuperPOD 레퍼런스 아키텍처와 관련된 상세한 기술 문서를 제공합니다.
- www.nvidia.com/dgx-superpod 페이지에서 DGX SuperPOD에 대한 개요와 주요 특징을 확인할 수 있습니다.
NVIDIA 백서: NVIDIA에서 발행하는 DGX SuperPOD 레퍼런스 아키텍처 백서를 요청하여 더 자세한 기술 정보를 얻을 수 있습니다.
함께 읽으면 좋은 콘텐츠