지난 3월, NVIDIA는 AI 모델을 최적화된 컨테이너로 제공하는 추론 마이크로서비스 플랫폼을 공개했습니다. 새로운 GPU 가속 NVIDIA NIM 마이크로서비스와 클라우드 엔드포인트 카탈로그가 공개되면서, AI 기술의 신속한 생산 및 배포의 길이 열렸죠.
NVIDIA는 업계 및 다양한 산업 전반에 걸쳐, AI 모델의 개발 가속화를 위해 NIM 마이크로 서비스를 적극적으로 권장하고 있습니다. 이 글에서는 NVIDIA NIM 서비스와 오픈소스 LLM으로, Generative AI 솔루션을 구축할 수 있는 방법에 대해 소개합니다.
NVIDIA NIM 주요 특징과 기능
특징
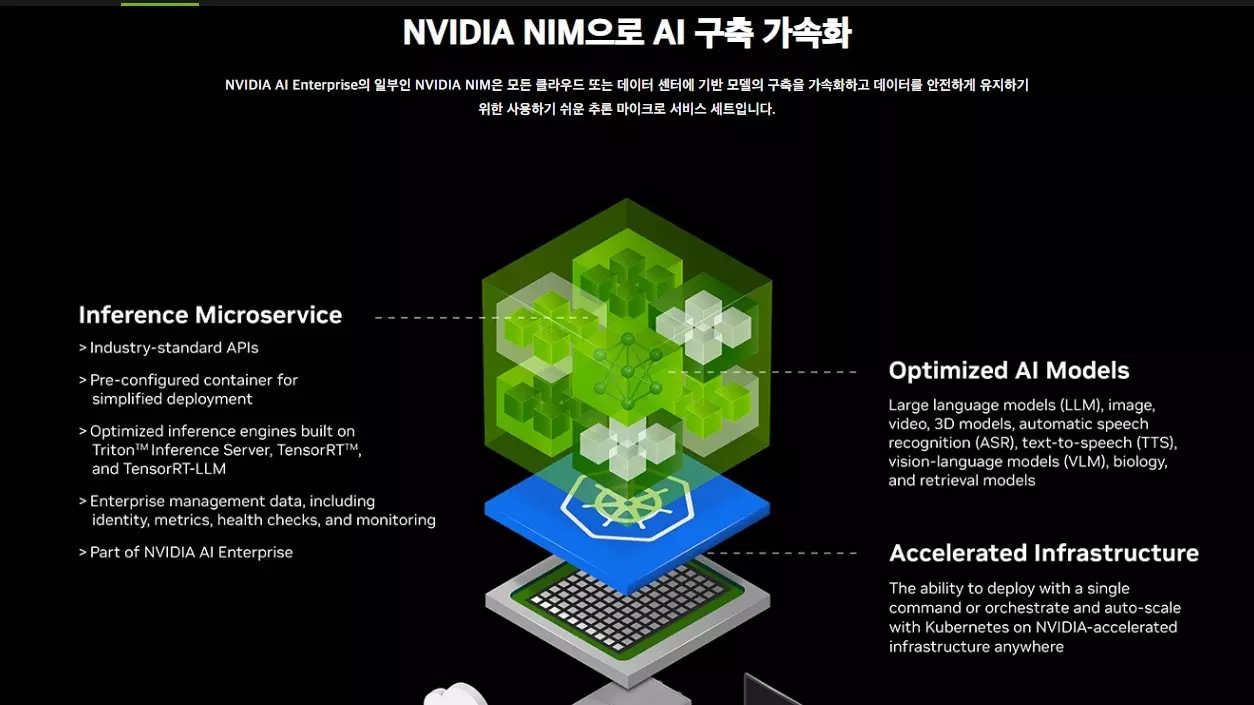
NVIDIA NIM(NVIDIA Inference Microservices)은 NVIDIA의 최첨단 AI 인프라 기술로, 기업과 개발자들이 생성형 AI 애플리케이션을 빠르고 효율적으로 구축, 배포, 확장할 수 있도록 지원하는 혁신적인 플랫폼입니다.
NIM은 음성 AI, 데이터 검색, 디지털 생물학, 디지털 휴먼, 시뮬레이션, 대규모 언어 모델(LLM) 등 다양한 분야에서 AI 솔루션을 구축하고 배포하는 데 사용될 수 있습니다.
NIM의 핵심 특징은 AI 모델을 최적화된 컨테이너 형태로 제공한다는 점입니다. 이는 빠른 배포와 확장을 가능하게 하며, 특히 GPU 가속 추론을 위해 사전 구축된 컨테이너를 제공함으로써 성능을 극대화합니다.
NVIDIA는 매월 다양한 산업과 도메인에 걸쳐 선도적인 AI 모델을 위한 NIM 마이크로서비스를 제공하고 있습니다.
주요 기능
최신 NIM 마이크로서비스는 다음과 같은 분야를 포함하고 있습니다.
- 음성 및 번역: Parakeet ASR-CTC-1.1B-EnUS(영어 음성 인식), FastPitch-HiFiGAN-EN(텍스트 음성 변환), Megatron 1B-En32(다국어 실시간 번역) 등의 모델을 제공합니다.
- 데이터 검색: NVIDIA NeMo Retriever QA E5, QA Mistral 7B 임베딩 모델, Snowflake Arctic Embed, QA Mistral 4B 재순위 모델 등을 통해 효율적인 정보 검색과 질문-답변 시스템 구축을 지원합니다.
- 디지털 생물학: MolMIM(분자 생성 및 최적화)과 DiffDock(분자 도킹) 모델을 제공하여 제약 회사의 약물 개발 워크플로우를 가속화합니다.
- 대규모 언어 모델(LLM): Llama 3.1 8B, 70B, 405B 모델을 제공하며, 특히 Llama 3.1 8B NIM은 NVIDIA H100 GPU에서 기존 대비 최대 2.5배의 성능 향상을 제공합니다.
- 시뮬레이션: OpenUSD 도구 개발을 위한 USD Code, USD Search, USD Validate 마이크로서비스를 제공합니다.
- 비디오 컨퍼런싱: Maxine Audio2Face-2D(2D 이미지 실시간 애니메이션)와 Eye Contact(시선 보정) 기능을 제공합니다.
최신 NIM 마이크로서비스들은 각 분야에서 최첨단 성능을 제공합니다. 예를 들어, Llama 3.1 8B NIM은 NVIDIA H100 데이터센터 GPU에서 배포 시 NIM을 사용하지 않을 때와 비교해 콘텐츠 생성에서 초당 토큰 수를 최대 2.5배 증가시킬 수 있죠.
NIM의 모듈식 특성은 기업이 특정 비즈니스 요구에 맞는 맞춤형 AI 솔루션을 구축할 수 있게 해줍니다. 음성 인식 NIM 마이크로서비스와 LLM NIM 마이크로서비스를 결합하여 의료, 금융, 소매 등 다양한 산업에서 개인화된 고객 서비스를 제공할 수 있습니다.
또한, NIM 마이크로서비스는 공급망 관리 시스템에 통합될 수 있습니다. 실제로, cuOpt NIM 마이크로서비스(경로 최적화용)를 NeMo Retriever NIM 마이크로서비스(RAG용)와 LLM NIM 마이크로서비스와 결합하여 기업이 자사의 공급망과 대화할 수 있게 합니다.
NVIDIA NIM을 활용한 LLM 최적화

LLM은 AI 혁신의 가장 중심부에 있는 기술이라고 해도 과언이 아닙니다. 더욱 발전할 LLM을 위해, NVIDIA NIM 마이크로 서비스는 다양한 애플리케이션과 언어에 걸쳐 눈에 띄는 성능과 정확성을 보여주고 있습니다.
예를 들어, NIM에서 Meta-Llama 3-8B 모델을 실행하면, NIM을 사용하지 않았을 때보다 최대 3배 더 많은 생성형 AI 토큰을 생성할 수 있습니다. 이를 통해, 동일한 컴퓨팅 인프라를 사용하더라도 더 많은 응답을 사용할 수 있어 효율성이 극대화되죠.
그렇다면 NIM의 어떤 점이 LLM 최적화에 영향을 주고 있는지 더 자세히 확인해 보겠습니다.
TensorRT-LLM을 이용한 추론 가속화
NVIDIA NIM은 오픈소스 LLM의 최적화에 특화된 혁신적인 기능을 제공합니다. 이 플랫폼의 핵심은 TensorRT-LLM을 활용한 추론 가속화에 있습니다. TensorRT-LLM은 NVIDIA GPU에서 LLM 추론 성능을 크게 향상시키는데, 이는 여러 고급 기술의 조합을 통해 이루어집니다.
먼저, 커널 융합 기법을 사용하여 여러 작은 연산을 하나의 큰 연산으로 통합함으로써 처리 효율을 높입니다. 이와 함께 양자화 기술을 적용하여 모델의 정밀도를 조절하는데, 이는 모델의 크기를 줄이면서도 성능을 유지하는 데 중요한 역할을 합니다.
특히 INT8 및 FP16 최적화를 통해 AI 워크로드를 가속화하며, NVIDIA H100 GPU에서는 더욱 효율적인 FP8 형식으로 모델 가중치를 쉽게 변환할 수 있습니다.
다중 GPU 확장성 구현
NVIDIA NIM의 또 다른 강점은 다중 GPU 확장성 구현에 있습니다. TensorRT-LLM은 다중 GPU 및 다중 노드 추론을 지원하여 대규모 병렬 처리를 가능하게 합니다.
이는 Python API의 전처리 및 후처리 단계와 통신 프리미티브를 활용하여 이루어지며, 특히 텐서 병렬화 기법을 통해 여러 GPU에서 동시에 처리를 수행함으로써 전체적인 처리량을 높이고 지연 시간을 줄입니다.
양자화 및 프루닝 기법 적용
더불어 NVIDIA NIM은 다양한 양자화 및 프루닝 기법을 적용하여 LLM의 성능을 더욱 향상시킵니다.
가중치 및 활성화 양자화를 통해 모델 크기를 줄이고 추론 속도를 높이는 한편, Adaptive Weight Quantization(AWQ)과 같은 고급 양자화 기법을 사용하여 모델 크기, 속도, 정확도 간의 최적의 균형을 찾을 수 있습니다.
또한 In-Flight Batching 기술을 도입하여 텍스트 생성 프로세스를 여러 실행 반복으로 나누어 GPU 활용도를 극대화합니다.
NIM 마이크로서비스 통합
이러한 첨단 기술들의 조합으로 인해 NVIDIA NIM은 강력한 최적화 기능을 활용하여 LLM 추론을 획기적으로 가속화하고, 이를 통해 기업들이 고성능 생성형 AI 애플리케이션을 쉽고 빠르게 구축하고 배포할 수 있습니다.
이외에도 NIM 마이크로서비스를 통해, 오픈소스 LLM에 다양한 기능을 추가할 수도 있는데요. 구체적인 내용은 아래에서 확인하실 수 있습니다.
음성 인식 및 번역 서비스 연동 (Parakeet ASR, Megatron NMT)
Parakeet ASR(Automatic Speech Recognition)은 최첨단 음성 인식 모델로, 특히 영어 음성 인식에서 뛰어난 성능을 보입니다.
이 모델은 11억 개의 매개변수를 가진 ASR-CTC-1.1B-EnUS 버전으로, 다양한 발화 패턴과 노이즈 레벨에 대해 높은 정확도와 견고성을 자랑합니다. 실시간 음성 텍스트 변환을 가능하게 하여, 음성 기반 애플리케이션의 사용자 경험을 크게 향상시킬 수 있죠.
Megatron NMT(Neural Machine Translation)는 실시간 다국어 번역을 위한 모델입니다. Megatron 1B-En32 버전은 32개 언어 쌍 간의 번역을 지원하며, 특히 영어를 중심으로 한 번역에서 높은 성능을 보입니다.
두 모델 모두 실시간 번역이 가능할 정도로 빠른 속도를 제공하면서도 높은 정확도가 장점인데요. Parakeet ASR과 Megatron NMT를 연동하면, 음성 입력을 실시간으로 인식하고 다른 언어로 번역하는 강력한 다국어 음성 통신 시스템을 구축할 수 있습니다.
검색 기능 강화 (NeMo Retriever)

NeMo Retriever는 NVIDIA의 최신 검색 기술로, 특히 질문-답변(QA) 시스템에 최적화되어 있습니다. 이 기술은 여러 가지 임베딩 모델을 제공하는데, 그 중 QA E5와 QA Mistral 7B 임베딩 모델이 주목할 만합니다.
이 모델들은 텍스트를 고차원 벡터 공간으로 변환하여 효율적인 검색을 가능하게 합니다. 특히 QA Mistral 7B 모델은 기존 대비 2배 향상된 처리량을 제공하여, 대규모 텍스트 코퍼스에서 빠르고 정확하게 정보를 검색할 수 있죠.
또한, NeMo Retriever는 Snowflake Arctic Embed와 QA Mistral 4B 재순위 모델을 포함합니다. Arctic Embed는 상업적 사용이 가능한 고성능 텍스트 임베딩 모델 스위트로, MTEB/BEIR 리더보드에서 각 크기 변형에 대해 최고 성능을 달성한 것으로 알려져 있습니다.
이외에도 QA Mistral 4B 재순위 모델은 검색된 문서의 관련성을 더욱 정확하게 평가하여 최종 결과의 품질을 높였습니다. 이 모델은 기존 대비 1.75배 향상된 처리량을 제공하죠.
멀티모달 기능 구현 (Maxine Audio2Face-2D 등)
멀티모달 기능 구현에 있어서는 Maxine Audio2Face-2D가 중요한 역할을 합니다. 이 기술은 음성 신호만을 사용하여 2D 이미지를 실시간으로 애니메이션화할 수 있습니다.
구체적으로, 입력된 음성 신호를 분석하여 해당하는 얼굴 애니메이션을 생성하고, 이를 H.264 압축 출력 비디오로 제공합니다. 또한 자연스러운 전달을 위한 헤드 포즈 애니메이션도 지원하며, 챗봇 출력이나 번역된 음성과 결합할 수 있습니다.
NIM의 확장 및 커스터마이징이 필요하다면?
실제 사용 사례
실제로 위와 같은 기능은 가상 에이전트 구현에 유용하게 사용되고 있는데요.
예를 들어, Parakeet ASR로 사용자의 음성을 인식하고, NeMo Retriever로 관련 정보를 검색한 뒤, Megatron NMT로 필요시 번역을 수행하고, 최종적으로 Maxine Audio2Face-2D를 통해 가상 에이전트의 얼굴을 애니메이션화하여 응답을 제공하는 것이죠.
NVIDIA NIM 마이크로서비스의 이러한 다양한 기능들은 서로 유기적으로 연동되어 강력한 생성 AI 솔루션을 구축할 수 있게 해줍니다.
이를 통해 기업들은 고도로 개인화되고 인터랙티브한 AI 애플리케이션을 효율적으로 개발하고 배포할 수 있으며, 궁극적으로 사용자 경험을 크게 향상시킬 수 있습니다.
NIM을 잘 활용하기 위해서는
NVIDIA NIM의 확장 및 커스터마이징은 기업의 특정 요구사항을 충족시키고 AI 솔루션의 성능을 최적화하는 데 핵심적인 역할을 합니다.
이를 위해서는 도메인 특화 파인튜닝 전략이 필수적입니다. 각 산업과 비즈니스 영역에는 고유한 용어, 컨텍스트, 데이터 구조가 존재하며, 이를 AI 모델에 효과적으로 반영하기 위해서는 전문적인 접근이 필요하기 때문이죠.
도메인 특화 파인튜닝을 통해 NIM의 기본 모델들을 특정 산업이나 사용 사례에 맞게 조정함으로써, 더욱 정확하고 관련성 높은 결과를 얻을 수 있습니다. 이 과정에서는 도메인 전문가의 지식과 AI 전문가의 기술적 노하우가 결합되어야 합니다.
새로운 마이크로서비스의 개발 및 통합 역시 NIM 플랫폼의 확장성을 극대화하는 데 중요한 요소입니다. 이는 단순히 기존 서비스를 조합하는 것을 넘어, 기업의 고유한 니즈를 충족시키는 완전히 새로운 AI 기능을 개발하는 것을 의미합니다.
이러한 작업은 NVIDIA의 기술에 대한 깊은 이해와 풍부한 경험을 필요로 하기 때문에, 전문 서비스 업체와의 협업이 매우 중요합니다.
아이크래프트는 NVIDIA 기술에 대한 깊은 이해와 풍부한 실무 경험을 바탕으로, 기업의 특성과 요구사항에 맞는 최적의 하이브리드 클라우드 전략을 수립하고 구현할 수 있는 역량을 갖추고 있습니다.
당사의 전문성은 단순히 기술적인 측면에 국한되지 않고, 비즈니스 프로세스 최적화, 비용 효율성 제고, 보안 강화 등 종합적인 관점에서의 솔루션을 제공하고 있습니다.
함께 읽으면 좋은 콘텐츠